- Posted
- Built with
- Python
Voice Sex Classifier
You can view the entire study here: https://github.com/vincemaina/speaker-identification/blob/main/vocal-sex-classifier/model/structured_data.ipynb
Or read the summarised version below.
Since starting my journey into machine learning, I’ve been particularly drawn to audio classification tasks. Given my background in music and audio engineering, it’s no surprise that this field fascinates me.
One of my earliest projects involved classifying birds by their calls and songs—a challenge I’d love to revisit. That experience taught me a valuable lesson: while deep learning models excel at uncovering complex patterns in audio that are difficult to extract manually, structured, hand-engineered features can also achieve strong results, especially when the classes are distinct.
Building on that insight, I decided to test a model that classifies voice recordings as male or female. Before diving into machine learning, I find it useful to consider how we, as humans, approach the same problem.
How Do We Recognize a Speaker’s Gender?
The most obvious answer is pitch—on average, men have lower-pitched voices than women. But is that the whole story?
What if a man and a woman had similar voice ranges—could we still tell the difference?
In reality, multiple factors distinguish male and female voices, including:
- Intonation – The way pitch varies over time; women often use a wider pitch range with more rising and falling patterns.
- Tonal quality – Factors such as breathiness, resonance, and formant frequencies.
- Speech rate – Women, on average, tend to speak faster than men.
Dataset Loading and Cleaning
For this task, I used the Common Voice dataset by Mozilla, which contains over 27,000 labeled voice recordings from speakers of various ages, genders, and backgrounds.
I had to remove samples with missing gender labels and ensure an even class distribution, as there were significantly more female samples than male.
Feature Extraction
I used parselmouth and librosa to extract key features such as:
- Fundamental frequency (pitch)
- Formants
- Spectral information
- MFCCs (Mel-frequency cepstral coefficients)
- Speech rate
Since many of these features produced arrays of values across the recording, I reduced them to three key statistics:
- Mean (average value over the recording)
- 10th percentile (low values)
- 90th percentile (high values)
This provided insight into the typical, low, and high values of each feature across the recording.
Feature Analysis
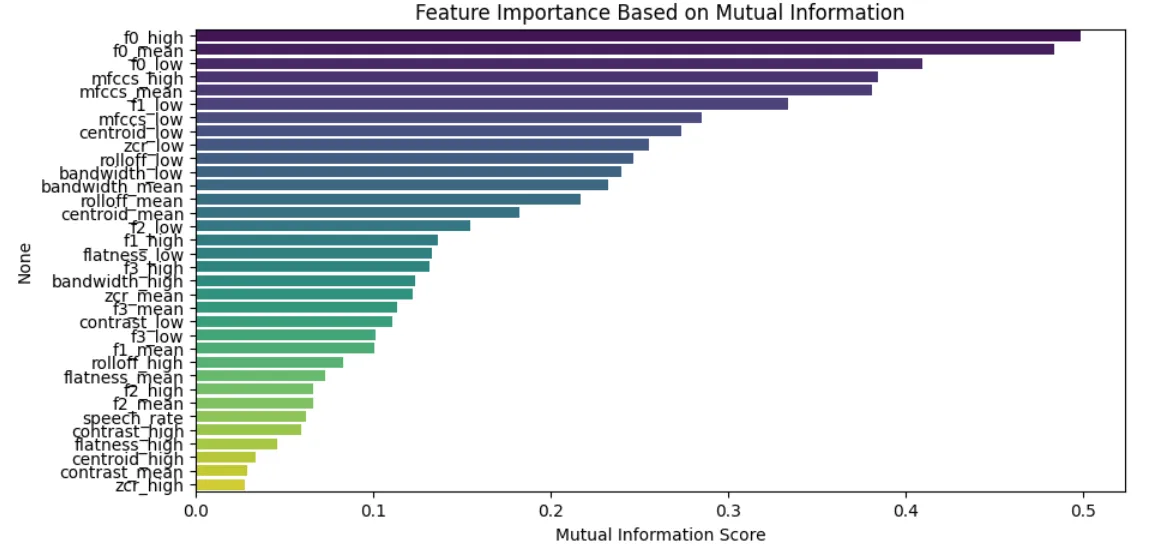
To determine which features had the strongest correlation with the target variable (gender), I applied different feature selection techniques.
Key Findings:
- Pitch (fundamental frequency, F0) was the most important feature, which is expected.
- Other features contributed to classification, but none had as strong an impact as pitch.
To check for multicollinearity, I used a correlation heatmap, highlighting only strong correlations:
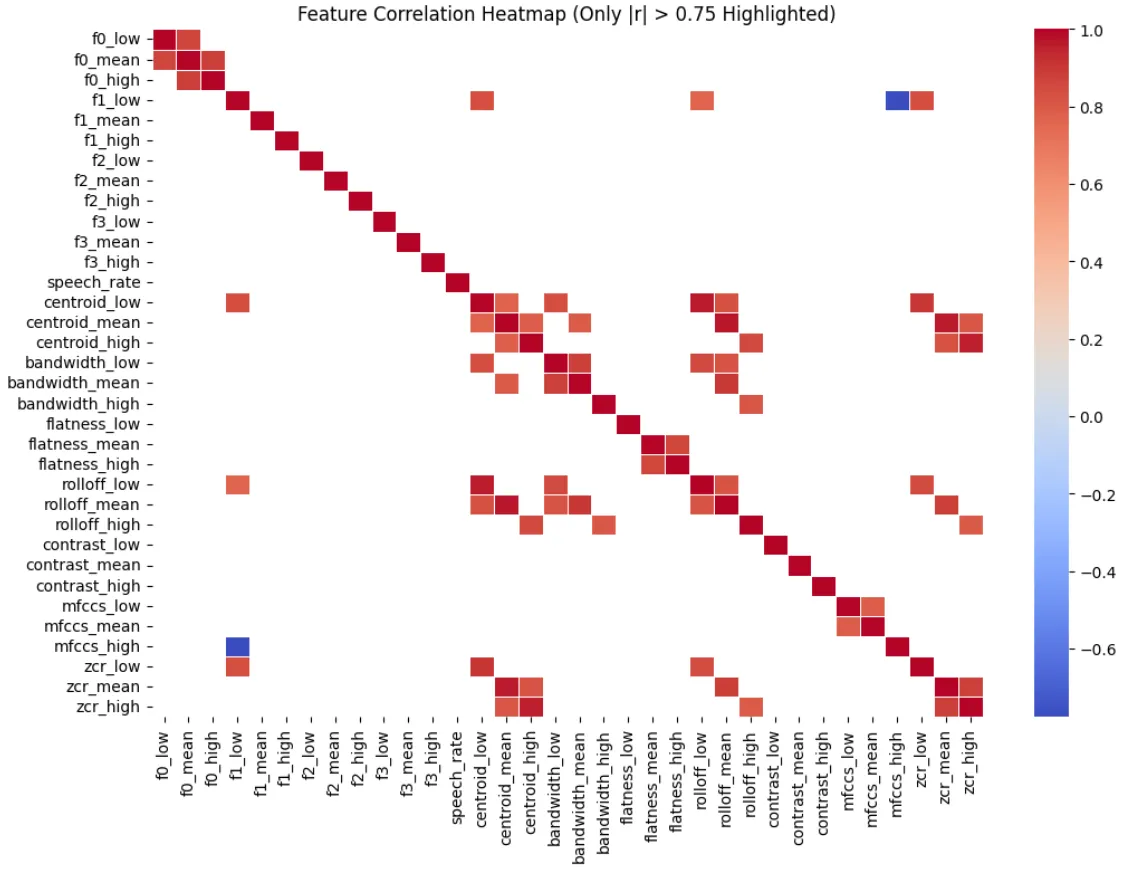
Many spectral features were highly correlated, which makes sense as they all relate to frequency content.
Feature Selection
With a baseline Random Forest model trained on all extracted features, I was already achieving 99% accuracy.
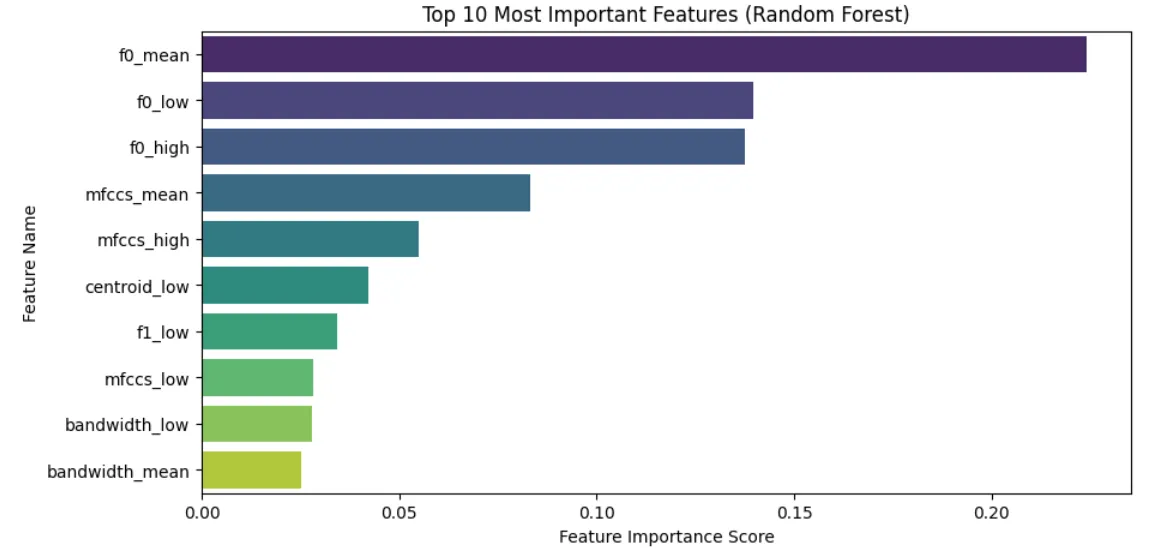
To improve efficiency, I used the model to determine feature importance and removed features with an importance level below 0.01.
I then retrained the model on this filtered feature set, and accuracy remained nearly identical.
Model Selection
I tested three different models:
- Random Forest
- Support Vector Machine (SVM)
- Multi-layer Perceptron (Neural Network)
Before training, I normalized the features using StandardScaler, as SVMs and Neural Networks perform better with normalized input.
Each model was evaluated using cross-validation:
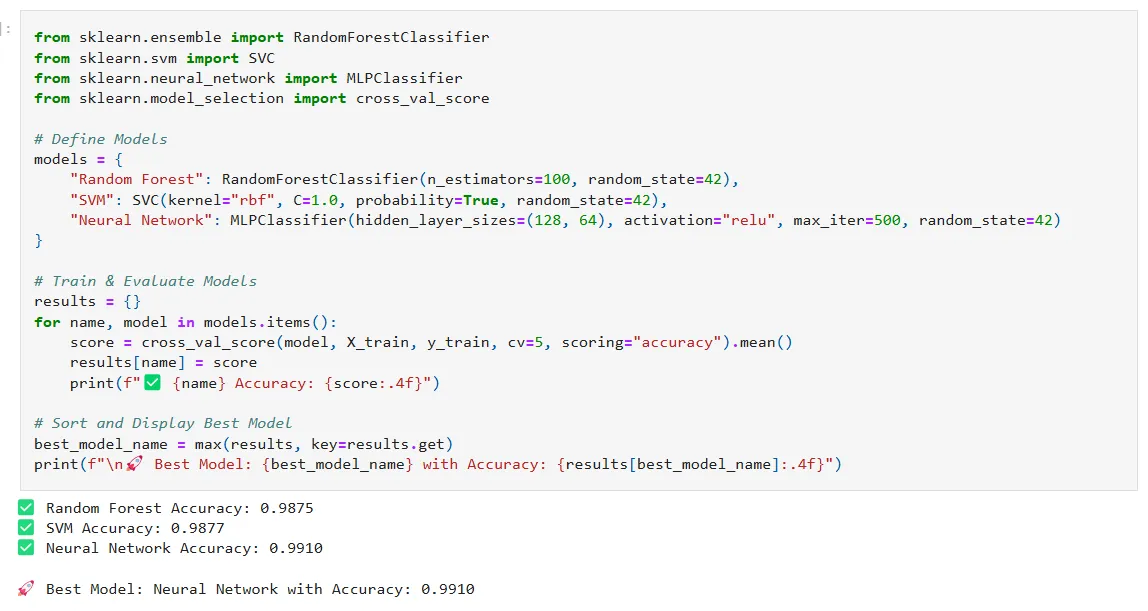
All models performed exceptionally well, each achieving an accuracy of approximately 99%.

The neural network generalized well, maintaining a 99% validation accuracy on the test data.
Final Thoughts
This project reinforced the idea that while deep learning models can automatically learn powerful representations, traditional methods using hand-crafted features can still yield exceptional results—especially for well-structured tasks like voice classification.
Next, I’d love to explore more nuanced aspects of vocal characteristics, such as emotion detection, speaker identity recognition, and prosody analysis.